
Scaling Intelligence & Generative Apps
First Principles Analysis of Gen AI

To be clear – all of the below thoughts are strictly my opinion and do not reflect those of Altimeter. No investment advice.
I live in the Bay Area where I spend an inordinate amount of time talking to early AI companies, late stage software companies, and founders and investors who support the whole ecosystem. I also spend a lot of time in New York, speaking with investors who are all brilliant in tracking the hard numbers of AI – CoWoS capacity out of TSMC, Nvidia H100 shipments, and timing “when AI revenues show up in guidance”. Having lived with this duality for over a year, I wanted to write a piece that captures some of my personal beliefs around AI.
One of the most topical questions I hear is “where are we in this AI cycle”? After a period of sheer exuberance from the investment community in Q1 of this year, for the past few months I’ve heard investors debating whether we are in a “trough of disillusionment” in AI. They’ve retracted and are bunkering down, debating whether or not we’ve overbuilt GPU supply, or if AI systems will ever reach production and be useful.
And I understand that. When I put my venture hat on, I see a lot of interesting companies building in the AI space, but it’s not as clear which moats are enduring, what layers of the stack are being commoditized, and valuations are sky high. And when I put my public market hat on, there have certainly been a lot of cycles burned through tracking Nvidia shipments and not a lot of revenue observed on the other end.
So where are we?
I was fortunate enough to begin my investing career at firms that place utmost importance on First Principles reasoning. Under that lens, I believe we can reframe the discussion around AI into first principles. “Why is AI a supercycle?”, and given that, “What can we expect?”.
There has been an incessant amount of prose written about Generative AI, so I will try my best to be concise. I believe Large Language Models represent a phase shift for humanity for three reasons:
LLMs fundamentally shift the cost curves for the price of reasoning
LLMs change the dynamics of “scaling intelligence”
LLMs will continue to scale UP in capability and scale DOWN in costs
The Economic Value of Reasoning
The nature / logic of software applications for the last 50 years has largely remained constant. SQL was developed in the 1970s and arguably all of today’s software applications can be summed up as a front-end UI/UX on top of a (relational) database. We’ve innovated on top of this with respect to infrastructure scaling, UI/UX, delivery medium, etc. but by and large software reduces back to a relational data schema for one reason: computers are deterministic and thereby, automation is deterministic.
To build an automated system today, one has to take a systems level view on a process, and isolate automatable pieces from tasks that require human judgment and reasoning. After doing this, build a mechanism for computer systems to complete the automated portion of the workflow. Because computers have a fundamentally lower cost curve to execute these tasks (compared to human labor) society benefits from improving labor productivity / lower cost of production of goods, software, and services.
For the last ~50 years of programmable computer science, we have always built machines this way – and it is precisely for this reason that the human ability to reason is one of the most highly valued skills in the world economy. It’s why Tesla had tried to automate the entire manufacturing process for its vehicles, only to determine that the optimal mix was automation with human participation. There were parts in the manufacturing process that required human judgment, generalization, and ultimately human manipulation for finer tasks. Humans have always had the capability of reasoning, inferring, abstracting, and generalizing – they are capable of non-deterministic thought.
This is why LLMs will fundamentally change the cost curves for humanity. LLMs are non-deterministic by nature. We have never had a computer that could do that. An LLM can take a non-deterministic (open ended) input in natural language, infer user intent from it, and – based on how an LLM application is built – generate a deterministic / semi-deterministic (hybrid) output. The takeaway here is not that LLMs will replace all human reasoning in the next year, but that we simply have not had the capability to build computer systems this way before. And with this new method unlocked, we will build new computer systems that have uniquely different capabilities, different cost curves, and different adoption patterns than we have for the last ~50 years.
Sam Altman shared this insight with us back in March:
“I think the right way to think of the models we create is as a reasoning engine, not a fact database. They can also act as a fact database, but that’s not really what is special about them.”
– Sam Altman, ABC News Interview published March 17, 2023
We are about to have our first major scale demo of this in a few short weeks as Microsoft launches Office 365 Copilot on November 1st. They have built Generative AI into their entire suite of products using a framework called Semantic Kernel which uses LLMs as a reasoning engine to ingest a user prompt and act upon it. Soon, you will be able to ask Microsoft Teams to summarize the meeting you missed, create a Powerpoint from your Word document, and build custom PowerBI dashboards from your own data, all with a natural language prompt. And all of those decisions will be made with LLMs interpreting a user’s query, deciding which of its tools it can use to solve the problem, and then executing on the task.
I invite you all to read the docs of Semantic Kernel, LangChain, and LlamaIndex as they all are building frameworks to shape model behaviors in various scenarios.
The Economic Value of Scaling Intelligence
Scaling intelligence is the title of this post because I believe it is the core of why the current LLM wave is a supercycle. I’m not quite sure why we’ve now normalized this fact, but the most performant model out there, GPT-4 already outperforms the average human on most standardized tests.

As GPT-4 approaches human-level reasoning capability, one of the key emerging use cases of LLMs for enterprises is retrieval augmented generation (RAG), a process where enterprises gather relevant contextual information to a user’s query and augments a user’s query with the relevant information. If this is a newer topic for you, watch the following video:
Here’s another good diagram, courtesy of LlamaIndex.

There’s been a lot of discussion over the last year over “which model will win”. While I think that question is intellectually interesting, I think it misdirects / focuses attention towards the wrong thing. There are real production use cases being built today which take advantage of the capabilities of vector search + retrieval combined with a powerful model (GPT-4/3.5, Claude 2, Llama 2, etc.) to solve real business problems. And it’s completely intuitive of why this is the case.
Consider how humans answer questions we don’t know the answer to. We first think about the question, we then search for the relevant data / context, and then we digest the information and respond. And if we’ve retrieved the correct relevant data / context - that answer will be right.
Retrieval Augmented Generation is built the same way. Retrieve the relevant context, and ask the language model to answer the user question, given the information provided. This turns the implementation of AI on its head – RAG becomes a solvable data retrieval problem, and the model becomes a “scaling intelligence” problem. And companies have the know-how to solve data retrieval problems and foundation model companies like OpenAI, Google, Anthropic, and Meta will continue to improve model intelligence.
If you believe that this marks a fundamentally different era / way to build computers – and derivatively that LLMs are now capable of non-deterministic thought (aka reasoning), then for the first time in history, we have a way to economically scale human thought.
It’s a similar idea to the one Elon has been articulating for years regarding Optimus (their humanoid robot).
Quote is at 25:34 of this Livestream
“What is an economy? An economy is productive entities times the productivity – capita times productivity per capita. At a point which there is no limitation on capita then it’s not clear what an economy even means at that point. An economy becomes quasi infinite.”
– Elon Musk, Tesla AI Day 2022, Sep 30, 2022
To Elon’s point, if you can affordably manufacture a human replacement at profitable unit economics, then you can scale GDP quasi-infinitely. The same is true for intelligence. If you can scale human reasoning infinitely, then you can then scale the downstream products of that – software and services – quasi-infinitely.
At the same time, the US population is expected to grow at a 0.35% CAGR through 2053, according to the Congressional Budget Office of the US – a majority of which is driven by net immigration. We aren’t growing GDP by increasing capita.
To add on, consider the incremental cost of a knowledge worker. The Brookings Institute estimates that the total expenditures to raise a child to age 17 is $310,605. Add incremental cost for a college degree at ~$200K for 4 years at a private university or $100K for a public college degree. About ~$500K fully loaded expenditure for an average new college grad. The average starting salary for a college graduate is $58,862 according to Bankrate so the effective “payback” on a new knowledge worker is 21 years of yielding minimal value to society, $500K of expenditure, to yield a ~10Y payback thereafter (assuming ALL salary is applied, ignoring expenditures and taxes). Let alone the cost to society with social security, programs, etc… Put that on a DCF.1
The analogy is not perfect and the math is illustrative at best, but at its core – we are not scaling humanity through population growth anymore. So to scale human reasoning further, we do need AI. Juxtapose this with the payback economics of a DGX 8xA100 Cluster from Nvidia. Based on this analysis I put together in Aug 2022, the paybacks – assuming a 50% discount to spot rates – is less than 2 years.
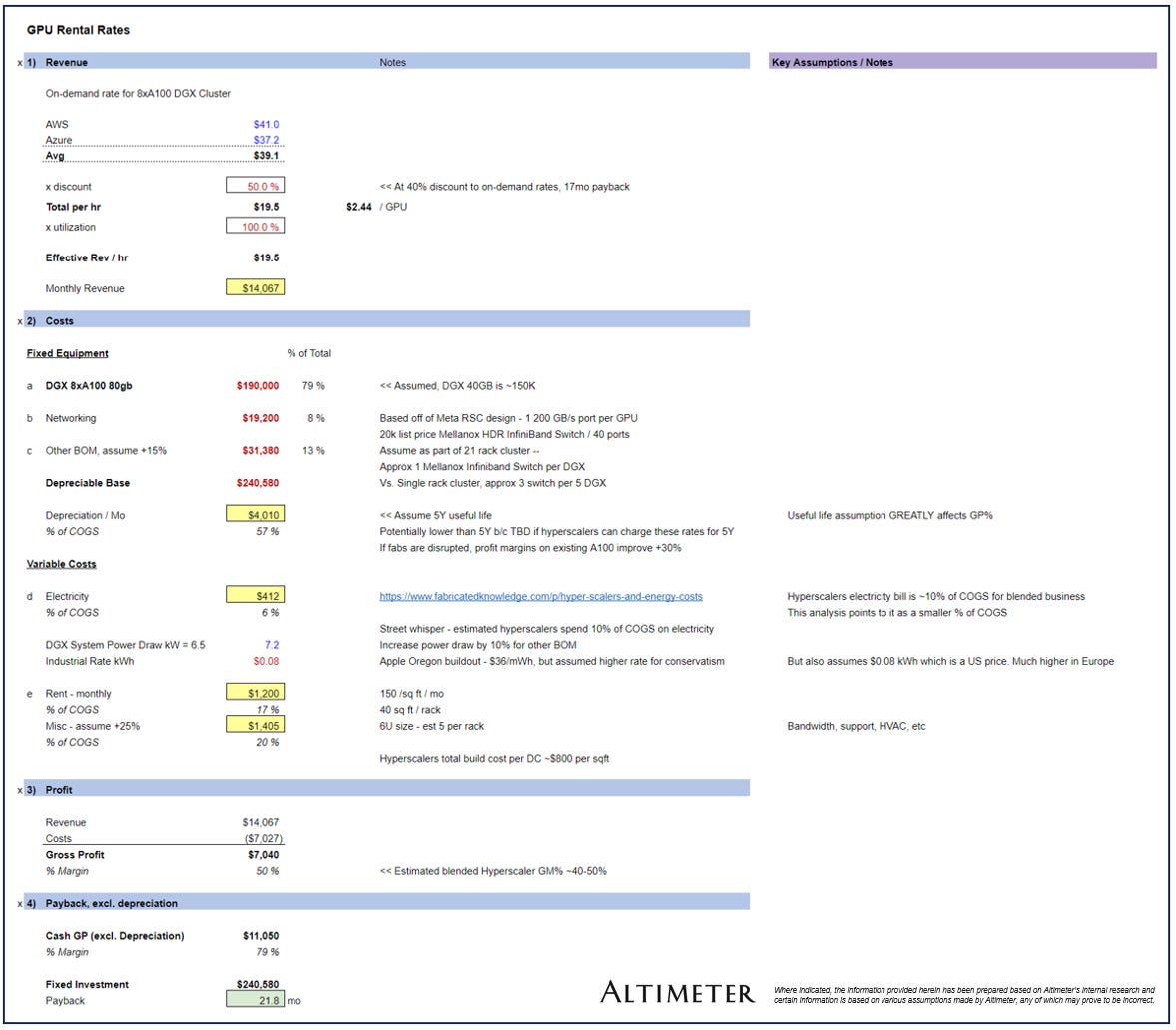
And since we’re on the topic of Nvidia, there is probably no better company to discuss this than them. Jensen has been speaking about this topic for months.
“In the future, every single major company will also have AI factories, and you will build and produce your company's intelligence… We cultivate and develop and nourish our employees and continue to create the conditions by which they can do their best work. We are intelligence producers already. It's just that the intelligence producers, the intelligence are people. In the future, we will be intelligence producers, artificial intelligence producers. And every single company will have factories, and the factories will be built this way.”
– Jensen Huang, CEO of Nvidia, at COMPUTEX 2023, May 30, 2023
Jensen began speaking of this “AI Factory” concept since Q4 FY23 earnings (February 22, 2023). Jensen had also been evangelizing the Transformer model in 2021, but no analyst would give him the time of day. When Jensen shares his view of the future, you should probably pay attention.
Why LLMs are Inevitably Getting Better
Ok I get it.
The models today are not perfect. They hallucinate. They can be biased. They’re expensive.
But they are getting better. I’ve spent a good amount of time also speaking with AI researchers in this last year. There are various ways and directions to improve the underlying performance of these models. But leave it to an expert to explain it – Dylan at SemiAnalysis has some of the best writings about these topics. But if we simplify it to its most basic elements:
More compute: In 2024, we will install more FLOPs (math operations / second) than we’ve ever cumulatively installed prior to 2023. Based on your projections for Nvidia, we are more than 2-3X’ing total installed compute capacity. And the mix of this is mostly Nvidia H100s which are the gold standard for model training. GPT-4 was trained on 25,000 Nvidia A100s – the prior generation of data center GPUs. H100s are roughly 3x the FLOPs / $ of an A100 and it is completely reasonable to assume the next generation of model may all be 10-100x the parameter count of the current generation of models.
More data: DeepMind released a paper in 2022, titled Training Compute-Optimal Large Language Models, affectionately dubbed the ‘Chinchilla Paper’ which detailed an optimal ratio between compute and amount of data a model is trained. While for a few months this year, we worried about running out of training data (current LLMs have majorly been trained on most of the internet already) it seems likely we will be able to avoid this with synthetic data generation. It is all but likely that the leading research labs OpenAI, DeepMind, and Anthropic have centered on this approach to scale their models proportionately to the vast amounts of compute they will soon have access to.
Algorithmic improvements: Again, Dylan discusses many of these topics in his (many) articles, but some of the more interesting algorithmic improvements available are Mixture of Experts (GPT-4 is a MoE model with multiple smaller “expert” models together), sparsity, and early token exit. Many of these improvements can be applied towards language models, but greater potential could lie within unlocking intelligence through multi-modality. OpenAI demonstrated that GPT-4 with vision performed better than GPT-4 with no vision. And that makes perfect intuitive sense – humans gain more context and understanding if they are able to associate words and concepts with images. Imagine you have perfect memory and are tasked with reading all the text on the internet – you’d know a lot, but if you were able to see all the images on the internet alongside the text, you’d be able to understand / explain much more. Unlocking intelligence from multiple modalities of data is something I’m probably most excited about. We are only beginning on this journey with aligning text models with image models, but think about the inherent logic, intelligence, and amount of data encoded into videos – a modality we’ve only barely begun to scratch.
The other axis of improvement is on inferencing.

We can go to varying levels of depth on this topic, but for simplicity, let’s break down some of these improvements into different buckets.
Hardware: Nvidia will continue to push out improvements with each generation it ships. Huang’s Law – named after Jensen – is an observation that the performance of GPUs on deep learning workloads will more than double every two years. The chart below details Nvidia single-chip inference performance over the last 10 years. A 1,000x improvement in 10 years, or 2^10 improvement. Note that this performance comes majorly through Nvidia’s own software which I attribute to “hardware improvement”.

Nvidia Chief Scientist Bill Dally said at Hot Chips 2023 that he attributes only 2.5x of the 1,000x improvement to process technology. Instead, much of the gains came from more efficient number representations and complex instructions sets. All of this is to say, we can continue to expect to gain performance from improvements from Nvidia and other hardware providers. In accordance with Huang’s Law – we should expect ~2x+ performance improvement from hardware each year.
Software: While Nvidia’s many improvements come in the form of software, there are other software improvements that can improve the underlying performance of inferencing models. For instance, as OpenAI supports inferencing at scale on GPT-4, techniques like caching and batching are important for amortizing fixed costs of inferencing (weights loading, instruction sets, etc.) over many user queries. This is systems engineering at its core and for a decade, engineers have solved similar types of problems at Google, Meta, Microsoft, etc. as they scaled to 1bn+ users. This is almost certainly the ripest area for innovation by OpenAI, Anthropic, Google etc. as they scale up inferencing & serving these models. I anticipate a significant 5 – 20x improvement in cost to serve models as these infrastructure systems mature and harden. This should come over the course of 1 – 2 years, but will certainly be front-end weighted as there is an immense amount of low-hanging fruit to be optimized. Remember, OpenAI just began serving requests at scale in December 2022.
Algorithmic: There are still many algorithmic improvements that can improve model inference. For instance, GPT-4’s MoE architecture allows it to only utilize ~280B of its ~1.8T parameters in a forward pass (generating one token). This expert network structure allows the model to continue scaling parameters, thereby “encoding more intelligence” while limiting the amount necessary at inference. There are other approaches that I am quite curious about like Google’s CaLM paper (and other approaches to reducing the need to complete the entire forward pass), but I will not pretend to be an expert. Leave that to all the researchers who are designing new architectures.

Considering all of this, I believe in two things:
It is inevitable that model performance will improve
There are many ways to improve model costs
The cumulative effect of all these factors almost certainly ensures that entities like OpenAI and Anthropic will significantly reduce inferencing costs further in upcoming months. Take a look at this comment by Greg Brockman, President of OpenAI in May 2023.
“We did a 70% price reduction 2 years ago, and basically this year we did a 90% cost reduction - basically a 10x cost drop - that’s crazy right? I think we're going to be able to do the same thing repeatedly with new models. So, GPT4 right now, it's expensive, it's not fully available, but that's one of the things that I think will change.”
– Greg Brockman, President at OpenAI at Microsoft Build (May 23, 2023)
What I’m Excited For
We’ve seen a few usage patterns emerge from enterprises leveraging LLMs. Enterprises are experimenting with a mix of the following:
Build an AI app with a proprietary model and RAG (use: GPT-4, Claude)
Fine-tune an open-source model like Llama 2 or one from Hugging Face
Buy a ready-built AI app from a startup. For instance, tools like Hebbia
Sometimes organizations may employ all of the above. What’s interesting when you talk to these forward-thinking enterprises, is that they have no problem proving ROI of any of these services. Instead they are experimenting with the various tools at their disposal because they need to make an informed decision of what approach is better. Each approach presents certain trade-offs. For instance, it’s really easy to get started / build a demo with GPT-4. It’s the best base model – but you don’t have control over it, and it’s expensive. Or in theory it’s great to fine-tune an open-source model – but that process to fine-tune it effectively is not as simple, and you have to manage more of your infrastructure yourself. It’s great to buy a product off the shelf, and you get a devoted team to build product for you, but how much of it can we do ourselves?
If you get a sense of déjà vu reading this, you’re not alone. It all sounds quite similar to early considerations for cloud adoption. My simple prediction is that this will evolve quite similarly to the adoption of the cloud.
Some enterprises (likely in regulated industries) will never move to proprietary models because they have very sensitive data that needs to live on-prem. They will fine-tune their own models and serve them with the help of some of services. Many companies will consume proprietary models through OpenAI, Anthropic, and Google, or through the hyperscalers. And some of the enduring vertical AI businesses that innovate at a blistering pace & attack a wide-enough / generalizable-enough problem will grow into sizeable AI vendors.
What I’m more excited about is what people will build. Today, most companies are experimenting with building chatbots with RAG, code completion tools, or customer service automation tools. This all makes logical sense as these have the most immediate ROI.
But if the costs on the most capable models are reduced by a factor of 10-20x, what will the world look like? This is something my colleague Freda and I have been thinking deeply about.
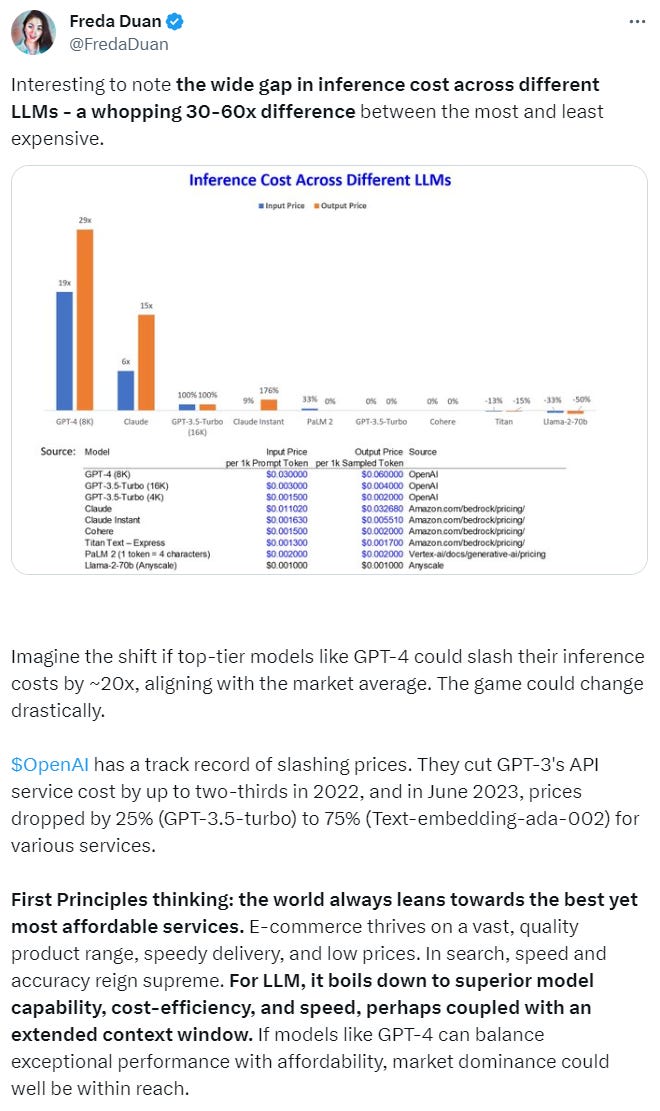
Unfortunately, Substack can no longer embed Tweets, but you can view the original post here.
The event I’m most looking forward to in the coming months is the November 1st launch of M365 Copilot. Based on all of my conversations with beta customers, the product is pretty astounding. Certainly not perfect and breaks a fair bit, but is certainly helpful with reducing many manual tasks. But probably the most astounding part of M365 Copilot is that a user can prompt a task in natural language, and the application can just do it. How does it work?

Microsoft built all of their Copilots using an SDK they open-sourced, called Semantic Kernel. I encourage everyone to watch these series by Alex Chao, one of the principal architects of Semantic Kernel.
What Semantic Kernel, LangChain, and LlamaIndex are focused on is building tools to make it easier to give agency to an LLM. In the case of Semantic Kernel:
A user makes a request in natural language
Semantic Kernel uses an LLM to interpret user intent
The Planner uses an LLM to create an action plan of how to accomplish the task
The Kernel calls on Skills (pre-defined functions an engineer has defined for the LLM like use a calculator, or populate data in column A), and Context / Data Connectors for more context
The Kernel executes the plan in accordance to the skills it has access to
Wow.
For the first time ever, we have a way to create a pseudo-human worker capable of taking an open-ended input and acting upon it. This definitely enters the realm of science fiction. Recall the initial magic of ChatGPT – the ability to prompt a chat window with any question and receive a coherent answer. I believe we could witness a similar moment with the rollout of M365 Copilot as enterprises experience the capabilities of a generative app / agent first-hand.
How else is Microsoft harnessing the reasoning ability of LLMs? Well aside from Semantic Kernel, Microsoft has also built a neat piece of software called Prompt Flow. According to the documentation, “Prompt flow is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications”.
One of the key challenges of building and maintaining AI applications at scale is evaluating model performance. If my AI application is serving hundreds of thousands of automated responses to my customers, how do I know if it’s serving relevant answers?
In the not-so-distant past of machine learning (circa 2021, to be precise), ML Engineers would maintain recommender models using MLOps tools, tracking model drift as an indicator to retrain their models. But with those ML models, you could measure model accuracy against a benchmark dataset.
How about with LLM apps? These models are generating completely new text – non-deterministically. How do you assign an accuracy threshold to natural language? And eye-balling certainly doesn’t scale.
Enter GPT-4, the cognitive worker.
“We use GPT-4 to look at the data you’re giving GPT-3.5 and the answer to score groundedness” – Seth Juarez, Principal PM, AI Platform at Microsoft Build 2023
To scale LLM apps, Microsoft decided to use GPT-4 as test evaluator of its GPT-3.5 model generations. This way, they could lower the cost of inferencing by allowing a smaller model – GPT-3.5 to generate a bulk of the calls, while leaving the high value tasks of evaluation with a larger, smarter model – GPT-4. Seem familiar? It eerily mirrors how human organizations operate. And that’s the point – for the first time, developers can build more human-like non-deterministic models. The possibilities are endless.
Trust me, the tools are not perfect, and M365 Copilot has many shortcomings, and things will break. But don’t forget, we are building computers in this manner for the first time in history. Microsoft started building these products just within the last 1.5 years – we will inevitably have kinks that we need to figure out. For instance with agents and RAG, there are silly issues relating to context length, chunking, that are being hacked around. And inferencing costs are high! But as enterprises realize the power of these generative apps, I’m sure they will be keen to develop.
As an outside investor, it’s easy to get bogged down with the challenges with running LLM production workloads at scale. But when you talk to builders, companies, and practitioners tinkering with LLMs, their excitement is evident. That’s because the issues they are running into are largely solvable. Rather, they’re actually fun to solve because you’re making real workarounds on the fly.
It’s been a long year for everyone engaged with AI. From researchers, to developers, to enterprises, to investors. The entire field is moving at a breakneck speed and it has been an exhausting year. But these moments are also the ones with maximum torque – maximum impact on the world. In five years’ time, we might not recognize our starting point… so buckle up!
The information presented in this newsletter is the opinion of the author and does not necessarily reflect the view of any other person or entity, including Altimeter Capital Management, LP ("Altimeter"). The information provided is believed to be from reliable sources but no liability is accepted for any inaccuracies. This is for information purposes and should not be construed as an investment recommendation. Past performance is no guarantee of future performance. Altimeter is an investment adviser registered with the U.S. Securities and Exchange Commission. Registration does not imply a certain level of skill or training.
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on, the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update the information or analysis contained herein in the future.
For fun, I ran this math. Assuming a 10% salary increase per year, it would take 33 years to break even. Pre-expenses & tax!
Great article - thanks for explaining in such an approachable way